Σκοπός
Η μελέτη της εξέλιξης της παιδικής γλώσσας και η περιγραφή των ιδιαίτερων χαρακτηριστικών της είναι ένα γνωστικό πεδίο που έχει απασχολήσει ερευνητές διάφορων επιστημονικών κλάδων συναφών με την ανάπτυξη του παιδιού. Μια τέτοιου είδους έρευνα απαιτεί την καταγραφή και την ανάλυση μεγάλου όγκου δεδομένων από την παιδική γλώσσα. Με την ανάπτυξη της τεχνολογίας, η συλλογή υλικού από την παρατήρηση/ καταγραφή του αυθόρμητου παιδικού λόγου και από τις πειραματικές μεθόδους διευκολύνθηκε σημαντικά. Σήμερα, η εκτεταμένη χρήση των τεχνολογιών στην ανάλυση της γλώσσας και η δυνατότητα δημιουργίας βάσεων δεδομένων έχει εξασφαλίσει την καταγραφή ενός μεγάλου όγκου υλικού από τον παιδικό λόγο, την κωδικοποίησή του και την αυτόματη ανάλυση μεταβλητών, συμβάλλοντας έτσι στην ανάπτυξη της επιστήμης της παιδικής γλώσσας με τεράστιες προοπτικές για το μέλλον. Η πιο γνωστή διεθνής βάση δεδομένων παιδικού λόγου αναπτύχθηκε στην Αμερική το 1984 και ονομάστηκε CHILDES. H βάση αυτή περιέχει δεδομένα και από την ελληνική γλώσσα, ωστόσο είναι περιορισμένης έκτασης.
Είναι φανερό ότι μια συλλογή γλωσσικού υλικού από παιδιά που καταγράφει σύγχρονα και διαρκώς αυξανόμενα δεδομένα, επιτρέποντας την ανάλυση και την εξαγωγή συμπερασμάτων για την αναπτυσσόμενη γλώσσα διευκολύνει και προωθεί τόσο τη μελέτη της φυσιολογικής ανάπτυξης της παιδικής γλώσσας όσο και της αποκλίνουσας, αλλά και τροφοδοτεί με κρίσιμα πορίσματα το χώρο της εκπαίδευσης και διδακτικής της γλώσσας. Το Προφορικό Σώμα Κειμένων Ελληνόφωνων Παιδιών (ΠΣΚΕΠ) έχει σαν σκοπό να διευκολύνει την έρευνα για τη γλωσσική ανάπτυξη δίνοντας σε φοιτητές και ερευνητές πρόσβαση σε υλικό για τη γλώσσα μικρών παιδιών με μητρική την Ελληνική. Το Σώμα αποτελείται από ψηφιακά αρχεία με συνομιλίες ενηλίκων και παιδιών το οποίο εμπλουτίζεται σταδιακά και προσφέρει τη δυνατότητα στο χρήστη να επιλέξει συνομιλίες χρησιμοποιώντας παράλληλα έναν συνδυασμό κριτηρίων αναζήτησης.
Περιγραφή
Το υλικό του ΠΣΚΕΠ αποτελείται από αυθεντικές συνομιλίες ενηλίκων και παιδιών (2,5 – 6+ ετών) που συγκεντρώθηκε με τη βοήθεια των φοιτητών (Πανεπιστήμιο Θεσσαλίας, Παιδαγωγικό Τμήμα Προσχολικής Εκπαίδευσης) στα πλαίσια του ετήσιου μαθήματος «Ανάπτυξη του λόγου στο παιδί» (από το 2015 και εξής) και επεξεργάστηκε στη συνέχεια από την ερευνητική ομάδας που συστάθηκε για τη δημιουργία βάσης δεδομένων: όλες οι συνομιλίες έχουν απομαγνητοφωνηθεί και καταχωρηθεί σε ξεχωριστά αρχεία. Το Σώμα προβλέπεται να συνεχίζει να εμπλουτίζεται σταδιακά.
Ο επισκέπτης του Σώματος μπορεί να επιλέξει να δει όλες τις καταχωρημένες συνομιλίες με τη σειρά, ή να επιλέξει κάποιες από αυτές εφαρμόζοντας κριτήρια αναζήτησης (φύλο ή ηλικία νηπίου, περιοχή ή ημερομηνία καταγραφής κ.ά.)
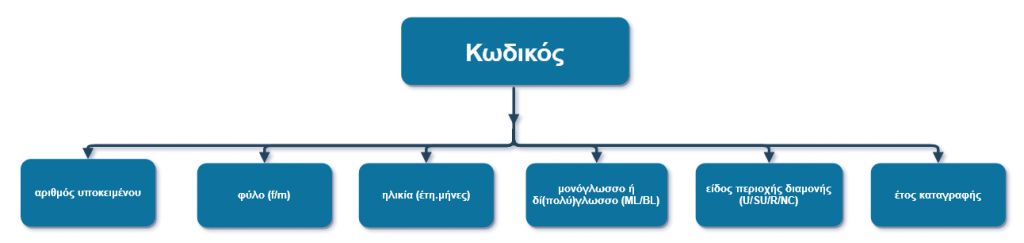
Στην αρχή κάθε συνομιλίας εμφανίζεται μια «καρτέλα στοιχείων» που δίνει πληροφορίες γι’ αυτή, όπως φύλο/ ηλικία νηπίου, τους συμμετέχοντες, το χώρο που γίνεται η καταγραφή κ.ά., καθώς και ένας κωδικός, μοναδικός για κάθε συνομιλία, που συνοψίζει εν μέρει τα στοιχεία της: αριθμός υποκειμένου (αύξουσα σειρά συνομιλίας στο corpus), φύλο (f/m), ηλικία (έτη.μήνες), μονόγλωσσο ή δί(πολύ)γλωσσο παιδί (ML/BL), είδος περιοχής διαμονής: αστική/ ημιαστική/ αγροτική/μη καταγεγραμμένη (U/SU/R/NC), έτος καταγραφής. Ακολουθεί το κείμενο της απομαγνητοφωνημένης συνομιλίας.
Ο λόγος του ερευνητή/-τριας ή άλλων συμμετεχόντων καταγράφεται ορθογραφικά. Κατά την κωδικοποίηση του παιδικού λόγου επιδίωξη ήταν να αποδοθούν και φωνητικές ιδιαιτερότητες/ αποκλίσεις. Έτσι, για την καταγραφή του, χρησιμοποιήθηκε κατά βάση το Διεθνές Φωνητικό Αλφάβητο, με ορισμένες προσαρμογές για διευκόλυνση της ανάγνωσης, στην κατηγορία των ουρανικών: έτσι, τα ουρανικά συμβολίζονται με [k’, g’, x’, n’, l’] (όμως κρατείται το σύμβολο [j] για το ουρανικό τριβόμενο ηχηρό).
Κατά την απομαγνητοφώνηση χρησιμοποιήθηκαν οι ελάχιστες δυνατές συμβάσεις/ σύμβολα, προκειμένου να διασφαλιστεί η κατά το δυνατόν ευχερής ανάγνωση της συνομιλίας. Τα σύμβολα που χρησιμοποιούνται είναι τα εξής:
- Οι παρατηρήσεις του ερευνητή που επεξηγεί/ σχολιάζει την περίσταση ή το λόγο του παιδιού μπαίνουν σε διπλή παρένθεση: (( ))
- Εάν κάποιος φθόγγος, λέξη, φράση κτλ δεν ακούγεται καλά τοποθετείται σε μονή παρένθεση/ μια άδεια παρένθεση στη θέση του ακατανόητου εκφωνήματος: ( )
- Σύμβολα που χρησιμοποιούνται για τους συμμετέχοντες στις συνομιλίες: Ε (Ερευνητής/-τρια), Ν (Νήπιο), Μ(ητέρα), Π(ατέρας) και Σ (οποιοσδήποτε άλλος συμμετέχων/-ουσα – για φιλικά ή λοιπά συγγενικά πρόσωπα νηπίου ή ερευνητών ή γονέων)
- Κεφαλαία: δηλώνουν αύξηση της έντασης της φωνής
- Αποσιωπητικά: δηλώνουν παύσεις στο λόγο
- Διπλά σύμβολα: δηλώνουν διάρκεια στην εκφώνηση
Ερευνητική ομάδα
Η ομάδα έργου που δημιούργησε το ΠΣΚΕΠ αποτελείται από τους:
Ελένη Μότσιου, Επίκουρη καθηγήτρια Παιδαγωγικού Τμήματος Προσχολικής Εκπαίδευσης του Πανεπιστημίου Θεσσαλίας, επιστημονικά υπεύθυνη
Θάνο Λίτσο, Μεταπτυχιακό φοιτητή του Τμήματος Αγγλικής Γλώσσας και Φιλολογίας του Αριστοτελείου Πανεπιστημίου Θεσσαλονίκης, υπεύθυνο για την κωδικοποίηση και επιμέλεια των αρχείων του Σώματος
Γιάννη Κυριαζή, Ηλεκτρονικό Μηχανικό ΤΕ στο Παιδαγωγικό Τμήμα Προσχολικής Εκπαίδευσης του Πανεπιστημίου Θεσσαλίας, υπεύθυνο για τη δημιουργία της ηλεκτρονικής βάσης δεδομένων και ιστοσελίδας του ΠΣΚΕΠ.
Το έργο υλοποιήθηκε με χρηματοδότηση της Επιτροπής Ερευνών (Ειδικός Λογαριασμός Κονδυλίων Έρευνας) του Πανεπιστημίου Θεσσαλίας.